How To: Configure Your Safe for Secure Protocol Operations
This guide explains how protocol teams should structure a production-grade Safe setup, designed for day-to-day execution and critical actions.
Safe{Wallet}
10 March 2026
)
As protocols mature, their operations become increasingly complex...
What begins as a multisig treasury wallet quickly becomes the execution layer for upgrades, parameter changes, governance actions, and emergency responses. At that stage, a Safe is no longer just holding value – it is a coordinating authority.
This guide explains how protocol teams should structure a production-grade Safe setup, designed for day-to-day execution and critical actions.
Why protocol operations need a dedicated Safe setup
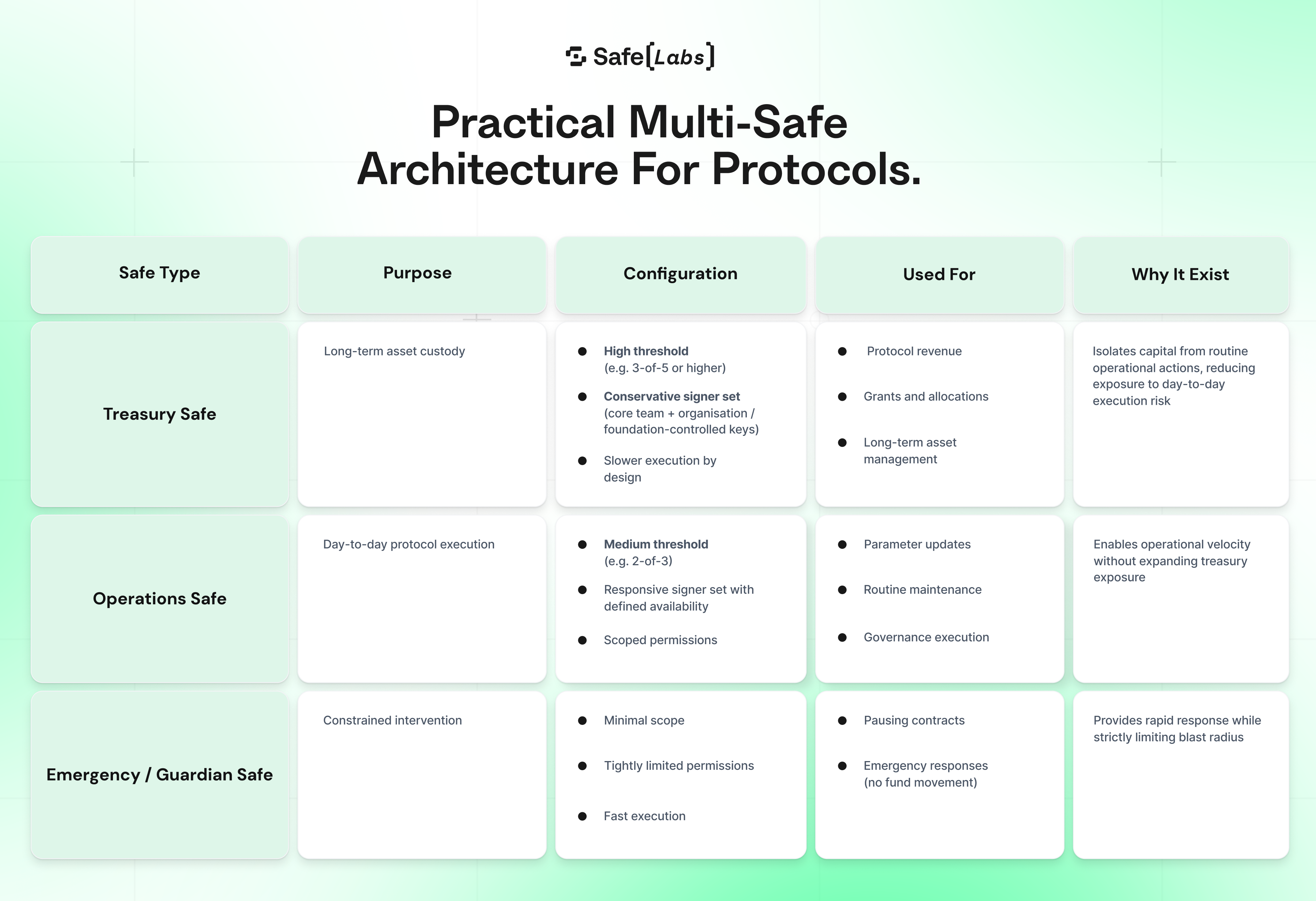
Protocol operations go beyond treasury management. As teams execute upgrades, parameter changes, and emergency actions, a single Safe quickly accumulates multiple responsibilities. Separating treasury, operations, and emergency authority into distinct Safes keeps execution predictable as complexity grows.
In the sections below, we’ll show how to implement a multi-Safe setup that supports secure, predictable protocol operations.
Production-grade Safe setup: Operational readiness checks
1. Scope & isolation: Can a mistake or compromise in one area affect the rest of the protocol?
Treasury actions should be isolated from ops and emergency actions
Emergency actions should not be able to move funds or upgrade contracts
Ops actions should not touch treasury assets
→ If treasury, emergency, and ops actions can impact each other: split responsibilities across multiple Safes and signers.
2. Authority & permissions: Is it obvious who can do what from the transaction alone?
Each Safe should have a clearly defined role (treasury/ops/emergency)
Permissions should restrict which contracts can be called and how
Sensitive actions must require the appropriate threshold
Add modules only if necessary. Complete due diligence before installing them.
→ If permissions are not unequivocal: scope permissions and review thresholds.
3. Signers & availability: Can this Safe execute when it needs to?
Keys should never be shared
Signers must be reachable and are expected to respond in a timely manner
Thresholds should balance speed and resilience
No single signer should be able to take unilateral control under pressure
Diversify signing devices for additional security
→ If a Safe can be blocked by unavailable signers: adjust the signer set and threshold.
4. Execution discipline: Do signers know exactly what they are approving?
Expected state changes must be understood before signing
Transactions should be simulated before approval
Signatures should be validated against the Safe transaction hash
Nothing should be approved “just to unblock execution”
Beware of blind signing
→ If transaction consequences can be unclear to signers: introduce mandatory simulation and review. See Hypernative Guardian.
5. Guardrails & monitoring: Are there system-level constraints beyond human review?
Guardrails should limit unsafe calls or transfers
Emergency authority must be tightly scoped
Monitoring and alerts should be enabled for unexpected behaviour
→ If the system is not set up to support human judgment: configure transaction guards and monitoring (e.g., policy-based guards, alerts). See Hypernative Guardian.
6. Continuity over time: Will this setup still work if the team or keys change?
Operational setups should assume change
Recovery should be configured to ensure continued access
The setup should be reviewed periodically as the organisation evolves
Consider how your organisation approaches signer rotation:
There are two schools of thought on signer rotation; teams should evaluate both. Some advocate scheduled rotation. This reduces long-term key exposure but requires governance changes, which can be targeted. Others prefer rotation only when a key is suspected or confirmed compromised. This avoids unnecessary governance changes but relies on compromise detection. Teams should assess their risk model and make the policy explicit.
→ If the setup fails when team members or keys change: add recovery and schedule periodic reviews.
Practical multi-Safe architecture for protocols
 Where to configure thresholds: Settings → Owners → Threshold
Where to configure thresholds: Settings → Owners → Threshold
Signing policy defaults
Well-designed setups avoid:
shared keys, which obscure accountability
unavailable signers, which can delay routine actions such as payroll, parameter updates, or maintenance
crisis centralization, where authority collapses to a single signer under pressure
Signer diversity across organisations, geographies, and hardware can further reduce correlated failure.
Guardrails to configure (recommended)
When a Safe can execute any action, every approval requires signers to assess scope, intent, and downstream impact. As transaction volume and urgency increase, this increases cognitive load and makes execution less predictable.
Guardrails address this by enforcing clear boundaries onchain. They can limit which contracts a Safe can call, restrict value transfers, and encode execution policies directly into the system.
This scoping also matters for emergencies. If the Emergency Safe is compromised, its impact should be deliberately limited. A properly scoped Guardian Safe can pause contracts, but cannot upgrade them, move funds, or execute arbitrary calls, keeping risk contained to the smallest possible surface.
A common guard setup is the Hypernative Guard, which implements custom policy enforcement, real-time monitoring, and alerts for production protocols.
Operational readiness by design
Operational complexity is a natural part of protocol growth.
A well-designed Safe setup absorbs that complexity and turns it into clear authority, predictable execution, and resilient coordination. With the right structure, protocol teams can operate confidently today and remain adaptable tomorrow.
Use the checks above before going live, and re-run them regularly as your protocol evolves. For deeper configuration details and best practices, explore Safe documentation.
Safe{Wallet}
10 March 2026
Copy link
